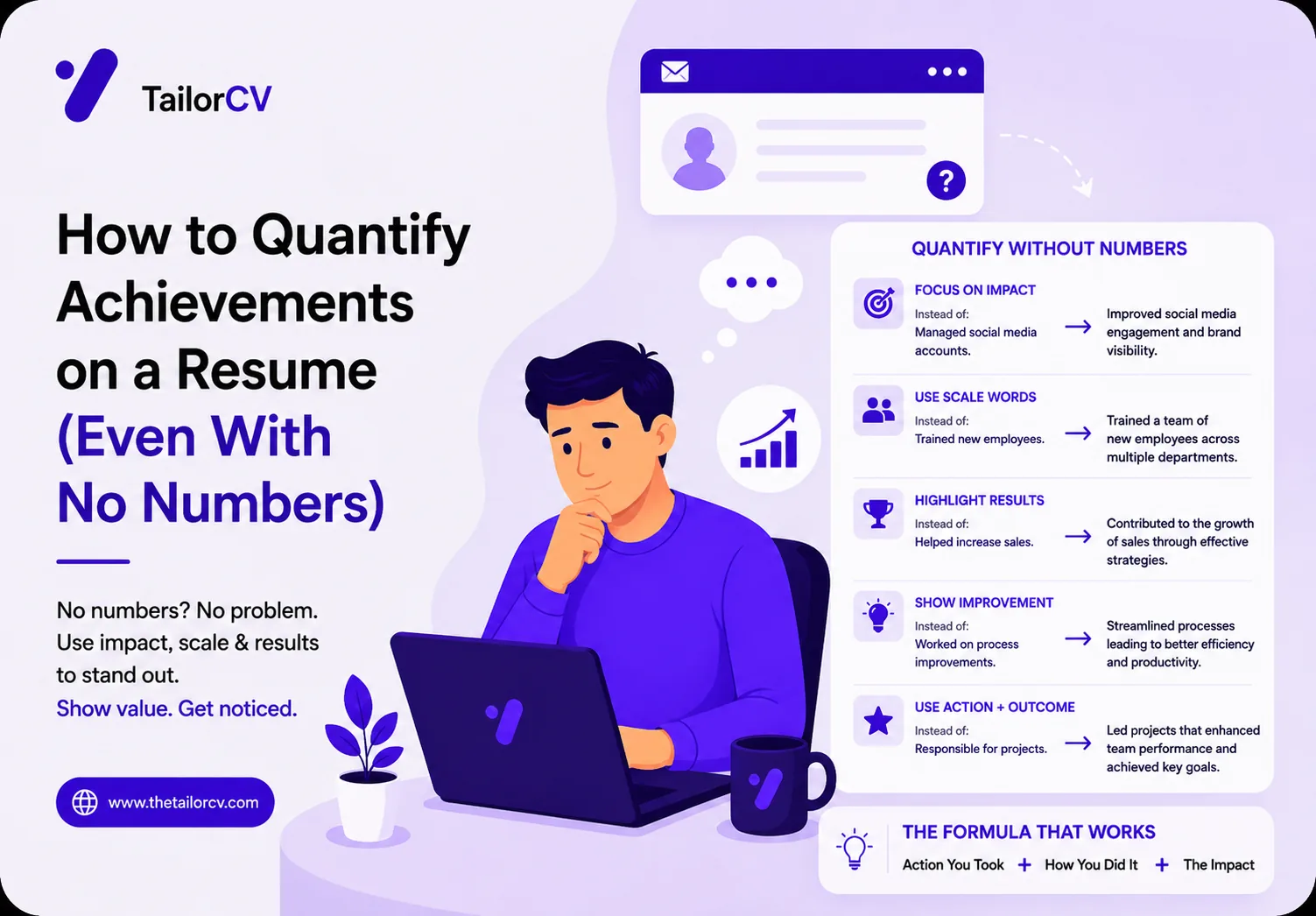
SS
SS

A machine learning engineer resume in 2026 sits at the intersection of software engineering and data science. You need to show that you can not only build and train models but also scale them, deploy them to production, monitor them for drift, and retrain them reliably. Pure data science skills are no longer enough for MLE roles - engineering discipline matters equally.
Companies building AI products are hiring ML engineers who can move fast without breaking production. If your resume only shows Jupyter notebooks and Kaggle competitions, it will not stand out against candidates who can ship ML systems end-to-end.
Before applying, run your resume through the ATS score checker and compare it against the job description. Read the resume optimization guide to make sure your skills section and experience bullets use the exact right terminology for ML roles. If you are also considering a pure research path, read the data scientist resume guide for comparison.
Key Takeaways
- A machine learning engineer resume in 2026 must demonstrate both model development and engineering skills, including deployment and monitoring.
- Resumes should be tailored to show experience in shipping end-to-end ML systems rather than just showcasing data science projects.
- The recommended resume format includes sections for summary, technical skills, work experience, projects, education, and publications, ideally fitting within one or two pages.
- Use specific keywords related to ML engineering, such as model deployment, MLOps, and feature engineering, to optimize for ATS systems.
- Strong resume bullet points should clearly articulate the impact and scale of projects, focusing on measurable outcomes and technical details.
Best ML Engineer Resume Format
- Header
- Summary
- Technical skills
- Work experience
- projects
- education
- Publications or open-source contributions
One page for engineers with under 8 years of experience. Two pages for principal or research-engineering roles with significant system design history.
ML Engineer Resume Summary
Formula:
ML Engineer with X years of experience building and deploying [model type or system] using [stack]. Strong in [training infrastructure, serving, monitoring, MLOps]. Delivered [measurable outcome].
Example for Experienced MLE
ML Engineer with 5 years of experience building production recommendation and ranking systems in Python, PyTorch, and TensorFlow. Deployed real-time model serving using TorchServe and Kubernetes, supporting 8M daily predictions with p99 latency under 40ms. Led retraining pipelines, feature store design, and model monitoring for 3 product teams.
Example for Entry-Level MLE
ML Engineer with strong Python, PyTorch, and scikit-learn skills. Deployed 4 ML models to production using FastAPI and Docker. Experienced with MLflow, feature engineering, model evaluation, and data pipeline construction. Seeking an ML engineer role at a team that values production-grade AI systems.
ML Engineer Technical Skills
Languages: Python, C++, Java, Scala ML Frameworks: PyTorch, TensorFlow, scikit-learn, JAX, Hugging Face Transformers MLOps Tools: MLflow, Kubeflow, Airflow, Weights and Biases, DVC Model Serving: TorchServe, TF Serving, FastAPI, BentoML, Triton Data and Features: Apache Spark, Kafka, Feast (feature store), Pandas, Dask Infrastructure: Docker, Kubernetes, AWS SageMaker, GCP Vertex AI, Azure ML Monitoring: Evidently AI, Prometheus, Grafana, custom drift detection Databases: PostgreSQL, Redis, MongoDB, BigQuery
Best ATS Keywords for ML Engineer Resume
- machine learning
- Deep learning
- Model deployment
- Model training
- Inference pipeline
- Feature engineering
- Feature store
- Model serving
- MLOps
- Distributed training
- PyTorch / TensorFlow
- Model monitoring
- Data drift
- Retraining pipeline
- Real-time inference
- Batch inference
- Kubernetes
- Docker
- AWS SageMaker
- GPU training
- Transformer models
- LLM fine-tuning
- A/B testing models
- Model versioning
- CI/CD for ML
How to Write ML Engineer Resume Bullet Points
Formula:
Built / Deployed / Designed + [ML system component] + [context or scale] + [latency, throughput, accuracy, or business result]
Weak Bullet Points
- Worked on machine learning models
- Trained deep learning models
- Used PyTorch for model development
- Improved model accuracy
Strong Bullet Points
- Designed and deployed a real-time product ranking model using PyTorch and TorchServe, serving 12M+ daily requests with p95 latency under 35ms on AWS EKS.
- Built an automated retraining pipeline with Airflow and MLflow that retrained the churn model weekly on fresh data and promoted models only when validation metrics improved, reducing model staleness from 90 days to 7 days.
- Implemented a feature store using Feast and Redis, reducing feature computation duplication across 6 ML models and cutting training data prep time by 65%.
- Fine-tuned a BERT-based text classifier on 200K domain-specific samples, achieving 91% F1 on intent classification versus 74% from the baseline zero-shot model.
- Reduced model training time by 3.2x by migrating single-GPU PyTorch training to 8-GPU distributed training using DDP on AWS EC2 P3 instances.
ML Engineer Resume Example
Senior ML Engineer E-commerce Platform | Jan 2023 - Present
- Led end-to-end development of a two-tower retrieval model for product recommendations, deployed to 6M daily users with a 14% increase in click-through rate.
- Built serving infrastructure using TorchServe, Kubernetes, and Prometheus, achieving 99.95% availability and p99 latency under 50ms at peak traffic.
- Designed a data pipeline using Apache Kafka and Spark Streaming to process 1.2M user events per hour for real-time feature updates.
- Implemented A/B testing for 4 model variants using a custom shadow deployment system, safely rolling out improvements without user-facing risk.
- Mentored 2 junior ML engineers on MLOps best practices, model evaluation, and production incident response.
Projects for Entry-Level ML Engineer
Good ML engineering projects to add:
- End-to-end ML pipeline with retraining
- Model serving API with FastAPI and Docker
- Fine-tuned language model
- Real-time fraud detection system
- Image classification with deployment
- Recommendation engine with vector search
Strong Project Example
Real-Time Fraud Detection API | Python, XGBoost, FastAPI, Redis, Docker
- Trained an XGBoost classifier on 500K synthetic transaction records with engineered features including amount velocity, merchant category, and device fingerprint.
- Built a FastAPI serving layer with Redis caching for feature lookup, achieving sub-10ms inference latency.
- Containerized the full pipeline with Docker Compose including model server, feature service, and monitoring.
- Logged model predictions and confidence scores to PostgreSQL for periodic drift analysis.
Common ML Engineer Resume Mistakes
Mistake 1: All theory, no production
Showing that you understand gradient descent is not enough. Show that you deployed a model, handled traffic, and monitored it for degradation.
Mistake 2: No scale numbers
Serving 100 requests is very different from serving 10M. Mention your system's scale wherever you have it.
Mistake 3: Weak MLOps coverage
In 2026, ML engineers who do not understand MLflow, feature stores, monitoring, or retraining pipelines are at a disadvantage for senior roles.
Mistake 4: Treating MLE like a data science role
MLE resumes should look more like software engineer resumes than data scientist resumes - emphasize systems, latency, reliability, and scalability alongside model accuracy.
Related Guides
- Data Scientist Resume
- Backend Developer Resume
- Chemical Engineer Resume
- Civil Engineer Resume
- Cloud Engineer Resume
- Cybersecurity Engineer Resume
- Data Engineer Resume
- Electrical Engineer Resume
- Embedded Systems Engineer Resume
- Game Developer Resume
- Mechanical Engineer Resume
- Python Developer Resume
- QA Engineer Resume 2026 - Complete Guide with Examples
- Site Reliability Engineer (SRE) Resume 2026 - Complete Guide
- DevOps Engineer Resume 2026 - Complete Guide with Examples
- Software Engineer Resume for FAANG in 2026
Make This Practical
Once you draft this resume, test it against a real job post with the free ATS score checker. Then improve fit using Resume Matching With Job Description, polish the layout with ATS-friendly resume templates, and make the bullets stronger with How to Write Resume Bullet Points.
A complete application needs more than one document. Pair the resume with a targeted letter from the AI cover letter generator, practice role-specific questions with the AI mock interview tool, and publish proof of work with the portfolio website builder when your role benefits from projects or case studies.
Conclusion
A strong ML engineer resume in 2026 shows that you can build reliable, scalable ML systems from data ingestion to production monitoring - not just train accurate models in notebooks.
Upload your resume to the TailorCV ATS score checker to see how well it matches your target ML engineer job description. Then use the technical interview preparation guide to prepare for ML system design, coding, and model evaluation rounds.
Frequently Asked Questions
How do I optimize my machine learning engineer resume for ATS?
To optimize your resume for ATS, ensure it includes relevant keywords from the job description. Utilize the ATS score checker to analyze your resume and make adjustments based on the feedback. Incorporate specific terms related to MLOps, model deployment, and Python to enhance your chances of getting noticed by hiring systems.
What should I include in the summary section of my ML engineer resume?
Your summary should succinctly highlight your experience and expertise. Use the formula: "ML Engineer with X years of experience building and deploying [model type or system] using [stack]. Strong in [training infrastructure, serving, monitoring, MLOps]. Delivered [measurable outcome]." This format allows you to present your qualifications clearly and effectively to potential employers.
How can I showcase my projects effectively on my resume?
When showcasing projects, focus on those that demonstrate your ability to deploy models and work with MLOps. Include a brief description of each project, your specific role, the technologies used, and the outcomes achieved. For ideas on impactful projects to include, check out our guide on fresher resume projects that get interviews.
What skills are essential for a machine learning engineer in 2026?
In 2026, essential skills for a machine learning engineer include proficiency in programming languages like Python, experience with MLOps tools, and an understanding of model deployment and monitoring. Highlight these skills prominently in your resume's technical skills section to align with what employers are seeking in candidates.
How does the ML engineer role differ from that of a data scientist?
The primary distinction lies in the focus of their responsibilities. While data scientists often concentrate on analyzing data and building models, machine learning engineers are responsible for deploying those models into production and ensuring their performance. For a deeper comparison, refer to our data scientist resume guide for insights on the differences in skills and experience.